Final Review
Nama : Sheila Gracia Angelina
NIM : 2301857456
Kelas : CB01 - CL
Lecturer : Ferdinand Ariandy Luwinda (D4522) dan Henry Chong (D4460)
Linked List













Binary Search Tree (BST)


- InOrder

- Post Order







Code Double Linked List dalam Aplikasi Supermarket
Untuk code bisa dilihat melalui link berikut:
https://data-structure-sheila.blogspot.com/2020/04/contoh-code-double-linked-list-in-c.html
atau file .cpp melalui link berikut:
https://drive.google.com/open?id=16IF9KQfsdpy098GK2osXbmAsgErl_AXu
AVL Tree
Pada Binary Search Tree (BST) bisa terjadi kasus dimana treenya berbentuk skewed karena berdasarkan inputan user. Contohnya bisa dilihat pada gambar di bawah ini.










 Secara umum, ada dua jenis heap:
Secara umum, ada dua jenis heap:
1. Min Heap
 Insertion pada Min Heap
Insertion pada Min Heap
 - Insert (5)
- Insert (5)


Deletion pada Min Heap


2. Max Heap
 Insertion pada Max Heap
Insertion pada Max Heap

Deletion pada Max Heap


MIN MAX HEAP

Insertion
Contoh:
- Insert (50)
 >Upheapmin : 50 is larger than its parent, so do upheapmax
>Upheapmin : 50 is larger than its parent, so do upheapmax
>Upheapmax : 50 is larger than its grand-parent, so swap their value
 > Upheapmax : because node 50 doesn’t have grand-parent, the process is finished
> Upheapmax : because node 50 doesn’t have grand-parent, the process is finished
Deletion
Ada dua jenis deletion pada Min Max Heap, yaitu delete min, dan delete max
- Delete Min = menghapus node terkecil, yaitu root
- Delete Max = menghapus node terbesar, yaitu salah satu dari anak root
Konsep deletenya sama seperti heap biasanya, yaitu node yang dihapus digantikan oleh node index terakhir lalu lakukan downheapmin jika delete min, atau downheapmax jika delete max.
Contoh:
- Delete Max
 > Replace the max value and replace it with last node (14)
> Replace the max value and replace it with last node (14)
 > Downheapmax : find the largest value from its children and grand-children. After that, swap their value.
> Downheapmax : find the largest value from its children and grand-children. After that, swap their value.
 > Downheapmax : because 14 parents is larger than 14, swap their value and continue downheapmax.
> Downheapmax : because 14 parents is larger than 14, swap their value and continue downheapmax.
 > Because 28 doesn’t have children or grand-children, the process is finished
> Because 28 doesn’t have children or grand-children, the process is finished
TRIES
 Contoh tries tersebut mengandung kata-kata:
Contoh tries tersebut mengandung kata-kata:
1. ALGO
2. API
3. BOM
4. BOS
5. BOSAN
6. BOR
NIM : 2301857456
Kelas : CB01 - CL
Lecturer : Ferdinand Ariandy Luwinda (D4522) dan Henry Chong (D4460)
Linked List
Linked List merupakan koleksi linear dari data, yang disebut sebagai nodes, dimana setiap node akan menunjuk pada node lain melalui sebuah pointer. Linked List dapat didefinisikan pula sebagai kumpulan nodes yang merepresentasikan sebuah sequence.
1. Circular Single Linked List
Single Linked List adalah sekumpulan dari node yang saling terhubung dengan node lain melalui sebuah pointer. Circular Linked List merupakan suatu linked list dimana tail (node terakhir) menunjuk ke head (node pertama). Jadi tidak ada pointer yang menunjuk NULL. Ada 2 jenis Circular Linked List, yaitu Circular Single Linked List dan Circular Double Linked List.
Circular Single Linked List adalah suatu linked list dimana tail menuju ke head dan hanya memiliki satu arah, serta tidak memiliki nilai NULL. Operasi Circular Single Linked List hampir sama dengan operasi pada Single Linked List.
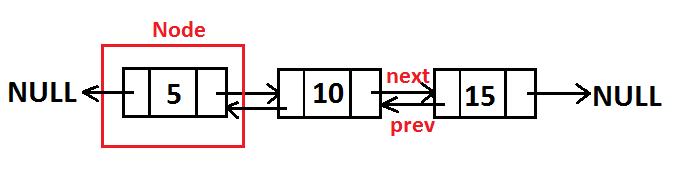
2. Doubly Linked List / Double Linked List
Sesuai namanya, Double artinya blok data yang kita miliki akan memiliki 2 penunjuk kiri dan kanan untuk menentukan data sebelum/sesudahnya. Berbeda dengan single linked list yang hanya mempunyai satu penunjuk, double linked list mempunyai 2 penunjuk kiri dan kanan untuk menentukan urutan datanya. Jadi, Double Linked List adalah elemen-elemen yang dihubungkan dengan dua pointer dalam satu elemen dan list dapat melintas baik di depan (head) atau belakang (tail). Elemen double linked list terdiri dari tiga bagian :
1. Bagian data informasi
2. Pointer next yang menunjuk ke elemen berikutnya
3. Pointer prev yang menunjuk ke elemen sebelumnya
Operasi yang biasanya ada di dalam sebuah doubly linked list pada dasarnya sama dengan yang ada di dalam single linked list, yakni:
1. Push / Insert
Sama seperti dalam single linked list, pertama kita harus mengalokasikan node baru dan menetapkan nilainya, dan kemudian kita menghubungkan node dengan linked list yang ada.
2. Pop / Delete
Ada 4 kondisi yang harus kita perhatikan saat melakukan Pop/Delete:
- Node yang akan dihapus adalah satu-satunya node dalam linked list.
- Node yang akan dihapus adalah head.
- Node yang akan dihapus adalah tail.
- Node yang akan dihapus adalah satu-satunya node dalam linked list.
- Node yang akan dihapus adalah head.
- Node yang akan dihapus adalah tail.
- Node yang akan dihapus bukan head atau tail.
3. Circular Doubly Linked List
Circular Doubly Linked List adalah linked list dengan menggunakan pointer, dimana setiap node memiliki 3 field, yaitu 1 field pointer yang menunjuk pointer berikutnya (next), 1 field menunjuk pointer sebelumnya (prev), serta sebuah field yang berisi data untuk node tersebut dengan pointer next dan prve-nya menunjuk ke dirinya sendiri secara circular.
Sekarang saya akan membahas mengenai coding operasi pada Linked List, yaitu push dan pop pada Single Linked List dan Double Linked List yang paling sederhana.
Pertama-tama, kita harus mendefinisikan struct untuk nodenya. Untuk lebih jelasnya bisa dilihat pada gambar di bawah ini.

1. Single Linked List
a) PUSH
Untuk push pada Single Linked List dapat dilihat pada gambar di bawah ini.

Pada coding di atas, kita menggunakan malloc untuk mengalokasikan memori secara dinamis. Setelah itu kita memberikan value kepada curr dengan nilai a. Dilanjutkan dengan kondisi if else. Jika kita baru push sekali, maka nilai pada head dan tail masih NULL. Oleh karena itu, jika nilai dari head adalah NULL maka head = tail = curr. Jika nilai dari head tidak NULL, maka nilai tail ke next adalah curr. Lalu nilai dari tail yang baru sama dengan nilai dari curr. Setelah kondisi tersebut, harus dideklarasikan nilai dari tail ke next adalah NULL.
b) POP
Untuk pop pada Single Linked List dapat dilihat pada gambar di bawah ini.

Pada coding di atas, kita mendefinisikan nilai dari curr sama dengan head. Dilanjutkan dengan kondisi if else. Jika nilai dari tail sama dengan head, maka nilai dari curr free / dihapus sehingga nilai dari head, tail, curr adalah NULL. Namun, jika nilai dari tail tidak sama dengan head, maka akan melakukan looping selama nilai dari curr ke next tidak sama dengan tail untuk menggeser nilai curr sampai sama dengan tail. Ketika nilai curr sudah sama dengan tail, maka nilai dari tail free / dihapus dan nilai dari tail yang baru adalah curr, sehingga tail ke next adalah NULL.
2. Double Linked List
a) PUSH
Untuk push pada Double Linked List dapat dilihat pada gambar di bawah ini.

Pada coding di atas, kita menggunakan malloc untuk mengalokasikan memori secara dinamis. Setelah itu kita memberikan value kepada curr dengan nilai a. Lalu mendefinisikan nilai dari curr ke next dan curr ke prev adalah NULL (artinya nilai sesudah dan sebelumnya adalah NULL). Dilanjutkan dengan kondisi if else. Jika kita baru push sekali, maka nilai pada head dan tail masih NULL. Oleh karena itu, jika nilai dari head adalah NULL maka head = tail = curr. Jika nilai dari head tidak NULL, maka nilai curr ke next adalah head dan nilai dari head ke prev adalah curr. Lalu nilai dari head yang baru sama dengan nilai dari curr.
b) POP
Untuk pop pada Double Linked List dapat dilihat pada gambar di bawah ini.

Pada coding di atas, terdapat kondisi if else. Jika nilai dari tail sama dengan head, maka nilai dari curr free / dihapus sehingga nilai dari head, tail, curr adalah NULL. Namun, jika nilai dari tail tidak sama dengan head, maka nilai dari tail adalah tail ke prev (nilai tail yang sebelumnya). Lalu nilai tail ke next free / dihapus sehingga nilai dari tail ke next adalah NULL.
Untuk memanggil fungsi push dan pop di atas, dapat dilihat pada gambar di bawah ini.

STACK
Stack (Tumpukan) adalah kumpulan elemen-elemen data yang disimpan dalam satu lajur linear. Kumpulan elemen-elemen data hanya boleh diakses pada satu lokasi saja yaitu posisi ATAS (TOP) tumpukan. Tumpukan digunakan dalam algoritma pengimbas (parsing), algoritma penilaian (evaluation) dan algoritma penjajahan balik (backtrack). Elemen-elemen di dalam tumpukan dapat bertipe integer, real, record dalam bentuk sederhana atau terstruktur. Sistem pengaksesan pada stack menggunakn sistem LIFO (Last In First Out), artinya elemen yang terakhir masuk itu yang akan pertama dikeluarkan dari tumpukan (Stack).
Operasi pada Stack adalah sebagai berikut :
1. Push : digunakan untuk menambah item pada Stack pada Tumpukan paling atas.
2. Pop : digunakan untuk mengambil item pada Stack pada Tumpukan paling atas.
3. Clear : digunakan untuk mengosongkan Stack.
4. Create Stack : membuat Tumpukan baru Stack, dengan jumlah elemen kosong.
5. MakeNull : mengosongkan Tumpukan Stack, jika ada elemen maka semua elemen dihapus.
6. IsEmpty : fungsi yang digunakan untuk mengecek apakah Stack sudah kosong.
7. Isfull : fungsi yang digunakan untuk mengecek apakah Stack sudah penuh.
3. Clear : digunakan untuk mengosongkan Stack.
4. Create Stack : membuat Tumpukan baru Stack, dengan jumlah elemen kosong.
5. MakeNull : mengosongkan Tumpukan Stack, jika ada elemen maka semua elemen dihapus.
6. IsEmpty : fungsi yang digunakan untuk mengecek apakah Stack sudah kosong.
7. Isfull : fungsi yang digunakan untuk mengecek apakah Stack sudah penuh.
Stack ada dua jenis, yaitu:
1. Stack dengan Array
Sesuai dengan sifat stack, pengambilan atau penghapusan elemen dalam stack harus dimulai dari elemen teratas.
2. Double Stack dengan Array
Metode ini adalah teknik khusus yang dikembangkan untuk menghemat pemakaian memori dalam pembuatan dua stack dengan array. Intinya adalah penggunaan hanya sebuah array untuk menampung dua stack.
QUEUE
Queue merupakan suatu struktur data linear. Konsepnya hampir sama dengan Stack, perbedaannya adalah operasi penambahan dan penghapusan pada ujung yang bebeda. Penghapusan dilakukan pada bagian depan (front) dan penambahan berlaku pada bagian belakang (Rear). Elemen-elemen di dalam antrian dapat bertipe integer, real, record dalam bentuk sederhana atau terstruktur.
Sistem pengaksesan pada Queue menggunakan sistem FIFO (First In First Out), artinya elemen yang pertama masuk itu yang akan pertama dikeluarkan dari Queue. Queue merupakan salah satu contoh aplikasi dari pembuatan double linked list yang cukup sering kita temui dalam kehidupan sehari-hari, misalnya saat anda mengantri diloket untuk membeli tiket.
Operasi pada Queue:
1. Create Queue : membuat antrian baru Q, dengan jumlah elemen kosong.
2. Make Null Queue : mengosongkan antrian Q, jika ada elemen maka semua elemen dihapus.
3. EnQueue : berfungsi memasukkan data kedalam antrian.
4. DeqQueue : berfungsi mengeluarkan data terdepan dari antrian.
5. Clear : Menghapus seluruh Antrian
6. IsEmpty : memeriksa apakah antrian kosong
7. IsFull : memeriksa apakah antrian penuh.
2. Make Null Queue : mengosongkan antrian Q, jika ada elemen maka semua elemen dihapus.
3. EnQueue : berfungsi memasukkan data kedalam antrian.
4. DeqQueue : berfungsi mengeluarkan data terdepan dari antrian.
5. Clear : Menghapus seluruh Antrian
6. IsEmpty : memeriksa apakah antrian kosong
7. IsFull : memeriksa apakah antrian penuh.
Hashing Table & Binary Tree
HASHING
Hashing adalah teknik untuk melakukan penambahan/insertion, penghapusan/deletion dan pencarian/searching dengan constant average time. Hashing merupakan teknik untuk mengubah berbagai key value menjadi berbagai indeks dari sebuah array. Untuk menambahkan data atau pencarian, ditentukan key dari data tersebut dan digunakan sebuah fungsi hash untuk menetapkan lokasi untuk key tersebut.
HASH TABLE
Hash table merupakan salah satu struktur data yang digunakan dalam penyimpanan data sementara. Tujuan dari hash table adalah untuk mempercepat pencarian kembali dari banyak data yang disimpan. Hash table menggunakan array sebagai medium penyimpanan dan menggunakan fungsi hash untuk menghasilkan sebuah indeks dimana suatu elemen harus dimasukkan atau ada. Hal ini menyebabkan waktu yang dibutuhkan untuk penambahan data (insertions), penghapusan data (deletions), dan pencarian data (searching) relatif sama dibanding struktur data atau algoritma yang lain.
Hash table menggunakan memori penyimpanan utama berbentuk array dengan tambahan algoritma untuk mempercepat pemrosesan data. Pada intinya hash table merupakan penyimpanan data menggunakan key value yang didapat dari nilai data itu sendiri. Untuk setiap key, digunakan fungsi hash untuk memetakan key pada bilangan dalam rentang 0 hingga H-size-1. Dengan key value tersebut didapat hash value.
Kelebihan dari hash table antara lain sebagai berikut:
– Hash table relatif lebih cepat
– Kecepatan dalam insertions, deletions, maupun searching relatif sama
HASH FUNCTION
Hash function merupakan suatu fungsi sederhana untuk mendapatkan hash value dari key value suatu data. Kita akan menggunakan operator modulo untuk mendapatkan berbagai key value. Yang perlu diperhatikan untuk membuat hash function adalah:
– ukuran array/table size(m),
– key value/nilai yang didapat dari data(k),
– hash value/hash index/indeks yang dituju(h).
Ada banyak cara untuk hash dari string ke key. Berikut adalah beberapa metode penting hash function:
- Mid-square
Kuadratkan string/Identifier dan kemudian menggunakan angka bit tengah untuk mendapatkan hash-Key. Jika key adalah string, maka akan dikonversi ke angka.
Step:
1. Kuadratkan nilai key. K2
2. Ekstrak bit r tengah dari hasil yang diperoleh pada step 1
Fungsi: h (k) = s
k = key
s = hash key yang diperoleh dengan memilih r bit dari K2
- Division (most common)
Membagi string/Identifier dengan menggunakan operator modulus. Ini adalah metode yang paling sederhana untuk hashing sebuah integer x.
Fungsi: h(z) = z mod M
z = key
M = value yang digunakan untuk membagi key, biasanya menggunakan bilangan prima, ukuran tabel atau ukuran memori yang digunakan.
- Folding
Partisi string/Identifier menjadi beberapa bagian, kemudian tambahkan bagian bersama-sama untuk mendapatkan hash key.
Step:
1. Membagi key value ke dalam beberapa bagian
2. Tambahkan individual part (biasanya last carry diabaikan)
- Digit Extraction
Digit yang telah ditetapkan dari nomor yang diberikan dianggap sebagai alamat hash.
Contoh:
Misalkan x = 14.568
Jika kita mengekstrak digit pertama, ketiga, dan kelima, kita akan mendapatkan kode hash: 158.
- Rotating Hash
Gunakan metode hash (seperti metode division atau Mid-Square). Setelah mendapatkan kode hash/alamat dari metode hash, lakukan rotasi. Rotasi dilakukan dengan menggeser digit untuk mendapatkan alamat hash baru.
Contoh:
Misal alamat hash = 20021
Hasil rotasi: 12002 (membalik angka)
COLLISION
Collision berarti ada lebih dari satu data yang memiliki hash index yang sama, padahal seperti yang kita ketahui, satu alamat / satu index array hanya dapat menyimpan satu data saja. Untuk meminimalkan collision gunakan hash function yang dapat mencapai seluruh indeks/alamat. Karena memori yang terbatas dan untuk masukan data yang belum diketahui tentu collision tidak dapat dihindari.
Berikut ini cara-cara yang digunakan untuk mengatasi collision :
1. Closed hashing (Open Addressing)
Close hashing menyelesaikan collision dengan menggunakan memori yang masih ada tanpa menggunakan memori diluar array. Closed hashing mencari alamat lain apabila alamat yang akan dituju sudah terisi oleh data. 3 cara untuk mencari alamat lain tersebut :
a. Linear Probing
Apabila telah terisi, linear probing mencari alamat lain dengan bergeser 1 indeks dari alamat sebelumnya hingga ditemukan alamat yang belum terisi data, dengan rumus
(h+1) mod m.
b. Quadratic Probing
Quadratic Probing mencari alamat baru untuk ditempati dengan proses perhitungan kuadratik yang lebih kompleks. Tidak ada formula baku pada quadratic probing ini.
Contoh formula quadratic probing untuk mencari alamat baru:
h,(h+i2)mod m,(h-i2)mod m, … ,(h+((m-1)/2)2)mod m, (h-((m-1)/2)2)mod m
dengan i = 1,2,3,4, … , ((m-1)/2)
Maksud formula di atas adalah jika alamat h telah terisi, maka alamat lain yang digunakan adalah (h+1)mod m, jika telah terisi gunakan alamat (h-1)mod m, jika telah terisi gunakan alamat (h+4)mod m, jika telah terisi gunakan alamat (h-4)mod m, dan seterusnya.
Jadi jika m=23,maka nilai maksimal i adalah : ((23-1)/2)=11.
c. Double hashing
Sesuai dengan namanya, alamat baru untuk menyimpan data yang belum dapat masuk ke dalam table diperoleh dengan menggunakan hash function lagi. Hash function kedua yang digunakan setelah alamat yang dihasilkan oleh hash function awal telah terisi tentu saja berbeda dengan hash function awal itu sendiri.
Kelemahan dari closed hashing adalah ukuran array yang disediakan harus lebih besar dari jumlah data. Selain itu dibutuhkan memori yang lebih besar untuk meminimalkan collision.
2. Open hashing (Separate Chaining)
Pada dasarnya separate chaining membuat tabel yang digunakan untuk proses hashing menjadi sebuah array of pointer yang masing-masing pointernya diikuti oleh sebuah linked list, dengan chain (mata rantai) 1 terletak pada array of pointer, sedangkan chain 2 dan seterusnya berhubungan dengan chain 1 secara memanjang.
Kelemahan dari open hashing adalah bila data menumpuk pada satu/sedikit indeks sehingga terjadi linked list yang panjang.
TREE
Tree merupakan salah satu struktur data tidak linier yang menggambarkan hubungan yang bersifat hirarkis (hubungan one to many) antara elemen-elemen. Tree bisa didefinisikan sebagai kumpulan simpul / node dengan satu elemen khusus yang disebut root dan node lainnya. Subtree adalah tree yang terbagi menjadi himpunan-himpunan yang tak saling berhubungan satu sama lainnya. Berikut adalah istilah umum pada tree:
· parent : predecssor satu level di atas suatu node.
· child : successor satu level di bawah suatu node.
· sibling : node-node yang memiliki parent yang sama dengan suatu node.
· subtree : bagian dari tree yang berupa suatu node beserta descendantnya dan memiliki semua karakteristik dari tree tersebut.
· size : banyaknya node dalam suatu tree.
· height : banyaknya tingkatan/level dalam suatu tree.
· root : satu-satunya node khusus dalam tree yang tak punya predecssor.
· leaf : node-node dalam tree yang tak memiliki seccessor.
· degree : banyaknya child yang dimiliki suatu node.
Contoh:

DEGREE of TREE = 3
DEGREE of C = 2
HEIGHT = 3
PARENT of C = A
CHILDREN of A = B, C, D
SIBILING of F = G
ANCESTOR of F = A, C
DESCENDANT of C = F, G
BINARY TREE
Binary tree/pohon biner adalah pohon dengan syarat bahwa tiap node hanya memiliki boleh maksimal dua subtree dan kedua subtree tersebut harus terpisah. Sesuai dengan definisi tersebut, maka tiap node dalam binary tree hanya boleh memiliki paling banyak dua anak/child. Implementasi binary tree bisa dilakukan menggunakan linked list. Masing-masing node terdiri dari tiga bagian yaitu sebuah data/info dan dua buah pointer yang dinamakan pointer kiri dan kanan.
Node Pada Binary Tree
Jumlah maksimum node pada setiap tingkat adalah 2n, node pada binary tree maksimumnya berjumlah 2n-1.
Jumlah maksimum node pada setiap tingkat adalah 2n, node pada binary tree maksimumnya berjumlah 2n-1.
Tipe Binary Tree
1. PERFECT binary tree adalah pohon biner di mana setiap tingkat berada pada kedalaman yang sama.


{kind=link}
2. COMPLETE binary tree adalah pohon biner di mana setiap tingkat, kecuali yang terakhir, sepenuhnya diisi dan semua node yang sejauh mungkin kiri. Sebuah PERFECT binary tree pasti COMPLETE binary tree.


{kind=link}
3. SKEWED binary tree adalah pohon biner di mana setiap node memiliki paling banyak satu anak.
{kind=link}

4. BALANCED binary tree is a binary tree in which no leaf is much farther away from the root than any other leaf (different balancing scheme allows different definitions of “much farther”).


{kind=link}
Operasi Binary Tree
Operasi-operasi pada Binary Tree :
v Create : Membentuk binary tree baru yang masih kosong.
v Clear : Mengosongkan binary tree yang sudah ada.
v Empty : Function untuk memeriksa apakah binary tree masih kosong.
v Insert : Memasukkan sebuah node ke dalam tree. Ada tiga pilihan insert: sebagai root, left child, atau right child. Khusus insert sebagai root, tree harus dalam keadaan kosong.
v Find : Mencari root, parent, left child, atau right child dari suatu node. (Tree tak boleh kosong)
v Update : Mengubah isi dari node yang ditunjuk oleh pointer current. (Tree tidak boleh kosong)
v Retrieve : Mengetahui isi dari node yang ditunjuk pointer current. (Tree tidak boleh kosong)
v DeleteSub : Menghapus sebuah subtree (node beserta seluruh descendantnya) yang ditunjuk current. Tree tak boleh kosong. Setelah itu pointer current akan berpindah ke parent dari node yang dihapus.
v Characteristic : Mengetahui karakteristik dari suatu tree, yakni : size, height, serta average lengthnya. Tree tidak boleh kosong. (Average Length = [jumlahNodeLvl1*1+jmlNodeLvl2*2+…+jmlNodeLvln*n]/Size)
v Traverse : Mengunjungi seluruh node-node pada tree, masing-masing sekali. Hasilnya adalah urutan informasi secara linier yang tersimpan dalam tree. Ada tiga cara traverse : Pre Order, In Order, dan Post Order.
Langkah-Langkahnya Traverse :
Ø PreOrder : Cetak isi node yang dikunjungi, kunjungi Left Child, kunjungi Right Child.
Ø InOrder : Kunjungi Left Child, Cetak isi node yang dikunjungi, kunjungi Right Child.
Ø PostOrder : Kunjungi Left Child, Kunjungi Right Child, cetak isi node yang dikunjungi.
IMPLEMENTASI HASH PADA BLOCKCHAIN
Blockchain adalah sistem pencatatan transaksi di banyak database yang tersebar luas di banyak komputer yang masing-masing memuat catatan yang identikal. Blockchain memiliki tiga mekanisme, salah satunya menggunakan teknik hash. Hash berguna untuk mendeteksi perubahan yang terjadi didalam blockchain. Teknik ini membuat blockchain lebih aman dan kredibel dalam menyimpan data-data penting karena jika ada yang mengubah satu blok dalam blockchain maka nilai hashnya akan berubah menjadi tidak valid. Lalu perubahan tersebut akan menyebabkan seluruh blockchain menjadi tidak valid.
Binary Search Tree (BST) adalah struktur data yang mengadopsi konsep Binary Tree namun terdapat aturan bahwa setiap clild node sebelah kiri selalu lebih kecil nilainya dari pada root node. Begitu pula sebaliknya, setiap child node sebelah kanan selalu lebih besar nilainya daripada root node. Jadi, Binary Search Tree adalah proses searching berbasis binary tree.
Tujuan membedakan kiri dan kanan sesuai besaran nilainya adalah untuk memberikan efiesiensi terhadap proses searching sehingga proses search akan lebih cepat.
Sifat Binary Tree:
- Setiap child node sebelah kiri harus lebih kecil nilainya daripada root nodenya.
- Setiap child node sebelah kanan harus lebih besar nilainya daripada root nodenya.
3 jenis cara untuk melakukan penelusuran data (traversal) pada BST :
- PreOrder
a. Cetak data pada root
b. Secara rekursif mencetak seluruh data pada subpohon kiri
c. Secara rekursif mencetak seluruh data pada subpohon kanan
a. Secara rekursif mencetak seluruh data pada subpohon kiri
b. Cetak data pada root
c. Secara rekursif mencetak seluruh data pada subpohon kanan
a. Secara rekursif mencetak seluruh data pada subpohon kiri
b. Secara rekursif mencetak seluruh data pada subpohon kanan
c. Cetak data pada root
Insert BST
Ketika insert sebuah node baru perlu diperhatikan operasi pencarian posisi yang sesuai. Dalam hal ini node baru tersebut akan menjadi daun/leaf.
Delete BST
Operasi delete memiliki 3 kemungkinan :
- Delete terhadap node tanpa anak/child (leaf/daun) : node dapat langsung dihapus
- Delete terhadap node dengan satu anak/child : maka node anak akan menggantikan posisinya.
- Delete terhadap node dengan dua anak/child : maka node akan digantikan oleh node paling kiri dari Sub Tree Kanan atau dapat juga digantikan oleh anak paling kanan dari Sub Tree Kiri.

Contoh delete BST:
1. Node (32) : dapat langsung dihapus sehingga akan dihasilkan tree sbb.

2. Node (8) : node dengan satu child

3. Node (72) : node dengan 2 child
Node akan digantikan oleh anak paling kanan dari Sub Tree Kiri (node(60))

Atau anak paling kiri dari Sub Tree Kanan (node(74))

Untuk code bisa dilihat melalui link berikut:
https://data-structure-sheila.blogspot.com/2020/04/contoh-code-double-linked-list-in-c.html
atau file .cpp melalui link berikut:
https://drive.google.com/open?id=16IF9KQfsdpy098GK2osXbmAsgErl_AXu
AVL Tree
Pada Binary Search Tree (BST) bisa terjadi kasus dimana treenya berbentuk skewed karena berdasarkan inputan user. Contohnya bisa dilihat pada gambar di bawah ini.

Input : 9 1 6 3 4
BST memiliki aturan dimana setiap inputan yang lebih besar dari root selalu ke kanan dan yang lebih kecil selalu ke kiri. Berdasarkan inputan user di atas, tree tersebut menjadi tidak seimbang. Oleh sebab itu, kita perlu menggunakan AVL Tree.
AVL Tree adalah balanced binary search tree dimana memiliki perbedaan tinggi antara subtree kiri dan kanan 0 atau 1. Tujuan dari AVL Tree ini adalah untuk menjadikan BST seimbang sehingga proses pencarian menjadi lebih mudah. AVL Tree ditemukan oleh Adelson-Veleskii dan E.M. Landis.
Height:
1. Jika subtree kosong maka height bernilai 0
2. Jika node adalah leaf maka height bernilai 1
3. Jika merupakan internal node, maka heightnya bernilai height maksimum anaknya ditambah 1
Balance Factor: perbedaan tinggi/height antara subtree kiri dan subtree kanan.
Contoh:

BST di atas tidak seimbang karena node 17 memiliki balance factor bernilai 2. Jadi, BST di atas bukan merupakan AVL Tree karena balance factornya lebih dari 1.
Operation pada AVL Tree ada 2, yaitu:
1. Insertion
2. Deletion
Insertion
Insert pada AVL Tree sama seperti insert pada BST, namun hal ini bisa menyebabkan BST menjadi tidak seimbang. Oleh sebab itu, setelah melakukan insertion maka harus menyeimbangkannya lagi / rebalance.
Ada 4 kasus yang biasa terjadi saat operasi insertion dilakukan, yaitu:
Misal: T adalah node yang harus diseimbangkan kembali
- Kasus 1: node terdalam terletak pada subtree kiri dari anak kiri T (left-left)
- Kasus 2: node terdalam terletak pada subtree kanan dari anak kanan T (right-right)
- Kasus 3: node terdalam terletak pada subtree kanan dari anak kiri T (right-left)
- Kasus 4: node terdalam terletak pada subtree kiri dari anak kanan T (left-right)

Untuk menyeimbangkan BST pada keempat kasus tersebut maka dilakukan rotation. Rotation ada 2 jenis, yaitu:
1. Single Rotation : jenis rotation ini dilakukan jika terjadi kasus 1 dan 2
2. Double Rotation : jenis rotation ini dilakukan jika terjadi kasus 3 dan 4
Contoh Single Rotation pada operasi Insertion:

Node yang diinsert adalah 12. Setelah melakukan insertion, didapatkan tree seperti pada gambar kiri. BST tersebut tidak seimbang karena balance factor pada node 30 lebih dari 1. Kasus tersebut sama seperti kasus 1, yaitu node terdalam terletak pada subtree kiri dari anak kiri T (left-left). Oleh sebab itu diseimbangkan menggunakan single rotation sehingga menghasilkan AVL Tree seperti pada gambar kanan dimana node 22 menjadi rootnya.
Contoh Double Rotation pada operasi Insertion:

Node yang diinsert adalah 26. Setelah melakukan insertion, didapatkan tree seperti gambar di sebelah kiri. BST tersebut tidak seimbang karena balance factor pada node 30 lebih dari 1. Kasus tersebut sama seperti kasus 4, yaitu node terdalam terletak pada subtree kiri dari anak kanan T (left-right). Oleh sebab itu diseimbangkan menggunakan double rotation. Jika menggunakan single rotation, tree tetap menjadi tidak seimbang. Pada rotation pertama menghasilkan BST seperti gambar di tengah, dimana node 22 menjadi anak dari node 27. BST masih belum seimbang. Pada rotation kedua menghasilkan BST yang seimbang sehingga didapatkan AVL Tree seperti pada gambar kanan dimana node 27 menjadi rootnya.
Deletion
Ada dua kasus pada opersi deletion dilakukan, yaitu:
- Jika node yang akan dihapus berada pada posisi leaf atau tanpa node anak, maka dapat langsung dihapus.
- Jika node yang akan dihapus memiliki anak, maka proses deletionnya perlu di cek kembali / rebalance untuk menyeimbangkan BST dengan balance factor maksimal 1.
4 kasus yang ditemukan akan rebalance:
Misal: T adalah node yang harus diseimbangkan kembali
- Kasus 1: node terdalam terletak pada subtree kiri dari anak kiri T (left-left)
- Kasus 2: node terdalam terletak pada subtree kanan dari anak kanan T (right-right)
- Kasus 3: node terdalam terletak pada subtree kanan dari anak kiri T (right-left)
- Kasus 4: node terdalam terletak pada subtree kiri dari anak kanan T (left-right)

Untuk menyeimbangkan BST pada keempat kasus tersebut maka dilakukan rotation. Rotation ada 2 jenis, yaitu:
1. Single Rotation : jenis rotation ini dilakukan jika terjadi kasus 1 dan 2
2. Double Rotation : jenis rotation ini dilakukan jika terjadi kasus 3 dan 4
Contoh Deletion:

Node yang akan dihapus adalah 60. Kemudian node 55 menggantikan posisi 60.

Hal tersebut membuat BST menjadi tidak seimbang. Balance factor pada node 55 lebih dari 1 sehingga perlu dilakukan rotation. Jenis rotation yang digunakan adalah single rotation karena kasus tersebut sama seperti kasus 2, yaitu node terdalam terletak pada subtree kanan dari anak kanan T (right-right).

Setelah melakukan single rotation pada node 55, maka dilakukan perbedaan tinggi kembali/ rebalance dimana balance factor bernilai maksimal 1. Didapatkan bahwa BST tersebut masih belum seimbang karena pada node 50 balance factornya lebih dari 1. Kasus tersebut sama seperti kasus 4, yaitu node terdalam terletak pada subtree kiri dari anak kanan T (left-right). Oleh sebab itu dilakukan double rotation.

Setelah dilakukan double rotation, didapatkan tree seperti gambar diatas. Tree tersebut sudah seimbang dan merupakan AVL Tree / Balanced BST.
==>>Hal penting pada AVL Tree adalah setiap melakukan insertion atau deletion, maka perlu terus memperhatikan balance factornya. Jika BST tersebut belum seimbang, maka harus diseimbangkan kembali/ rebalance. Proses rebalance bisa dilakukan menggunakan single rotation atau double rotation. Jenis rotation yang digunakan harus sesuai dengan kasus yang didapatkan agar tree menjadi seimbang. <<==
Heap and Tries
HEAP
Heap adalah complete binary tree berdasarkan struktur data yang memenuhi properti heap. Tujuan dari heap ini adalah untuk menemukan nilai terkecil pada min heap dan nilai terbesar pada max heap. Penulisan heap mirip dengan BST, namun pada heap, anak kiri tidak ada hubungannya dengan anak yang kanan. Heap dapat diimplementasikan menggunakan linked-list, tetapi jauh lebih mudah untuk mengimplementasikan Heap menggunakan array sehingga setiap elemen yang baru masuk ke array pada index terakhir yang kosong.

1. Min Heap
Setiap nilai elemen node lebih kecil daripada elemen anaknya (child). Dapat dilihat bahwa nilai elemen terkecil berada pada root dan elemen terbesar berada pada salah satu leaves node. Contoh min heap:
Saat melakukan insertion, kita harus mempertahankan properti heapnya. Pertama, memasukkan elemen baru ke akhir heap (setelah index elemen terakhir). Lalu, unheap elemen baru tersebut dan memperbaiki properti heapnya, misalnya pada min heap jika elemen baru lebih kecil dari rootnya maka posisinya harus ditukar, namun jika lebih besar maka properti heap sudah benar. Contoh:
- Insert (20)


Deletion pada Min Heap
Pada deletion, kita hanya memperhatikan deletion pada elemen terkecil yang terletak pada root. Pertama, ganti root dengan elemen terakhir dari heap. Lalu mengurangi jumlah elemen dalam heap. Setelah itu melakukan downheap (memperbaiki posisi heap). Proses downheap dilakukan dengan membandingkan current node dengan nilai anak kiri dan kanan lalu menukar current node dengan anak terkecil. Proses ini dilakukan terus sampai current node lebih kecil dari nilai anaknya atau saat current node adalah leaf (tidak memiliki anak). Contoh:
- Delete (7)

2. Max Heap
Setiap nilai elemen node lebih besar daripada elemen anaknya (child). Dapat dilihat bahwa nilai elemen terbesar berada pada root dan elemen terkecil berada pada salah satu leaves node. Contoh max heap:
Saat melakukan insertion, kita harus mempertahankan properti heapnya. Pertama, memasukkan elemen baru ke akhir heap (setelah index elemen terakhir). Lalu, unheap elemen baru tersebut dan memperbaiki properti heapnya, misalnya pada max heap jika elemen baru lebih besar dari rootnya maka posisinya harus ditukar, namun jika lebih kecil maka properti heap sudah benar. Contoh:
- Insert (15)
Deletion pada Max Heap
Pada deletion, kita hanya memperhatikan deletion pada elemen terbesar yang terletak pada root. Pertama, ganti root dengan elemen terakhir dari heap. Lalu mengurangi jumlah elemen dalam heap. Setelah itu melakukan downheap (memperbaiki posisi heap). Proses downheap dilakukan dengan membandingkan current node dengan nilai anak kiri dan kanan lalu menukar current node dengan anak terbesar. Proses ini dilakukan terus sampai current node lebih besar dari nilai anaknya atau saat current node adalah leaf (tidak memiliki anak). Contoh:
- Delete (20)
MIN MAX HEAP
Min Max Heap merupakan gabungan dari min heap dan max heap. Kondisi heap bergantian antara min heap dan max heap pada setiap level. Setiap elemen pada tingkat genap/ganjil lebih kecil dari semua anak-anaknya berarti min level. Sedangkan, max level berarti setiap elemen pada level ganjil/genap lebih besar dari semua anak-anaknya.

Tujuan dari Min Max Heap adalah memungkinkan kita untuk menemukan elemen heap yang terkecil dan terbesar pada waktu yang sama.
Pada Min Max Heap, elemen terkecil terletak pada root. Elemen terbesar terletak di salah satu anak root (kiri atau kanan). Elemen terbesar mungkin terletak pada root jika hanya ada satu elemen pada heap.
Insertion
1. Insert node baru pada index selanjutnya (setelah index terakhir)
2. Jika node baru tersebut terletak pada level min, maka bandingkan dengan parentnya.
- Jika parent < node maka swap dan upheapmax dari parentnya (lalu dibandingkan dengan grandparentnya dari posisi node setelah swap)
- Jika parent > node maka upheapmin dari posisi node (lalu dibandingkan dengan grandparentnya dari posisi node).
3. Jika key terletak pada level max :
- Jika parent > node maka swap dan upheapmin dari parentnya (lalu dibandingkan dengan grandparentnya dari posisi node setelah swap)
- Jika parent < node, upheapmax dari posisi node (lalu dibandingkan dengan grandparentnya dari posisi node)
Contoh:
- Insert (50)

>Upheapmax : 50 is larger than its grand-parent, so swap their value

Deletion
Ada dua jenis deletion pada Min Max Heap, yaitu delete min, dan delete max
- Delete Min = menghapus node terkecil, yaitu root
- Delete Max = menghapus node terbesar, yaitu salah satu dari anak root
Konsep deletenya sama seperti heap biasanya, yaitu node yang dihapus digantikan oleh node index terakhir lalu lakukan downheapmin jika delete min, atau downheapmax jika delete max.
Contoh:
- Delete Max




TRIES
Tries atau Prefix Tree adalah ordered tree pada struktur data yang digunakan untuk menyimpan array asosiatif (biasanya string). Istilah trie berasal dari kata retrieval (pengambilan) yang berarti mencoba menemukan satu kata dalam kamus hanya dengan awalan kata saja / prefix word. Tries merupakan sebuah tree di mana setiap vertex mewakili satu kata atau awalan. Root mewakili karakter kosong (").

1. ALGO
2. API
3. BOM
4. BOS
5. BOSAN
6. BOR
Tries biasanya digunakan untuk autocomplete pada saat searching di web. Tries juga digunakan untuk spell checker dan correction suggestion. Selain itu, ada beberapa game yang menggunakan konsep tries ini, salah satunya adalah Bubble Word.
Comments
Post a Comment